Table of contents
Open Table of contents
需求
-
master、data、ingest节点各3个
-
配置 x-pack ,使用ssl访问
环境
如果公司有内网dns,请带上二级域名,如:es-master-01.xxx.com
| hostname | system | ip | cpu | memory | disk | role |
|---|---|---|---|---|---|---|
| es-master-01 | centos 7.9 | 172.16.209.23 | 4c | 8g | 100 | lmr |
| es-master-02 | centos 7.9 | 172.16.209.230 | 4c | 8g | 100 | lmr |
| es-master-03 | centos 7.9 | 172.16.209.90 | 4c | 8g | 100 | lmr |
| es-data-01 | centos 7.9 | 172.16.209.179 | 4c | 4g | 100+500 | dlrt |
| es-data-02 | centos 7.9 | 172.16.209.150 | 4c | 4g | 100+500 | dlrt |
| es-data-03 | centos 7.9 | 172.16.209.123 | 4c | 4g | 100+500 | dlrt |
| es-ingest-01 | centos 7.9 | 172.16.209.116 | 4c | 8g | 100 | ilr |
| es-ingest-02 | centos 7.9 | 172.16.209.250 | 4c | 8g | 100 | ilr |
| es-ingest-03 | centos 7.9 | 172.16.209.89 | 4c | 8g | 100 | ilr |
部署
基础设置
基础设置是所有节点都要操作的
关闭firewalld
systemctl disable firewalld
关闭selinux
sed -i '/SELINUX/s/enforcing/disabled/' /etc/selinux/config
关闭swap
swapoff -a
配置hosts
cat >> /etc/hosts << EOF
172.16.209.23 es-master-01
172.16.209.230 es-master-02
172.16.209.90 es-master-03
172.16.209.179 es-data-01
172.16.209.150 es-data-02
172.16.209.123 es-data-03
172.16.209.116 es-ingest-01
172.16.209.250 es-ingest-02
172.16.209.89 es-ingest-03
EOF
内核优化
如果原先有相应字段的配置,改成对应值
net.ipv4.tcp_retries2:网络故障重传的次数;设置成5是为了es可以尽快的处理故障节点,具体详细解释参考官方文档:https://www.elastic.co/guide/en/elasticsearch/reference/8.9/system-config-tcpretries.html
vm.max_map_count:单个进程可以分配的内存映射区域的最大数量;es默认使用mmapfs目录来存储其索引。操作系统对mmap计数的默认限制可能过低,这可能会导致内存不足的异常。
cat >> /etc/sysctl.conf << EOF
vm.max_map_count = 262144
net.ipv4.tcp_retries2 = 5
EOF
sysctl -p
部署es
在所有节点操作
下载rpm包
wget https://artifacts.elastic.co/downloads/elasticsearch/elasticsearch-7.8.1-x86_64.rpm
安装es
rpm -ivh elasticsearch-7.8.1-x86_64.rpm
修改内存限制为无限制
sed -i '43a LimitMEMLOCK=infinity' /usr/lib/systemd/system/elasticsearch.service
master节点配置
只在master节点配置
修改es配置文件
PATH:/etc/elasticsearch/elasticsearch.yml
master节点上的配置文件基本一样
其他master节点修改node.name的值即可
# 集群名称,所有节点统一
cluster.name: es-cluster
# 该节点名称
node.name: es-master-01
# 该节点不做为data节点
node.data: false
# 该节点不做为ingest节点
node.ingest: false
# 该节点的data目录,可自定义,自定义需注意所属用户和权限
path.data: /var/lib/elasticsearch
# 该节点的log目录
path.logs: /var/log/elasticsearch
# 开启内存锁,服务启动的时候锁定足够的内存,防止数据写入swap
bootstrap.memory_lock: true
# 监听地址,可以配置为本机地址,这里写的是任意地址
network.host: 0.0.0.0
# 监听端口,可自定义,但后面配置自定发现的时候要加上端口
http.port: 9200
# 自动发现机器中的node节点
discovery.seed_hosts: ["172.16.209.179", "172.16.209.150", "172.16.209.123", "172.16.209.116", "172.16.209.250", "172.16.209.89"]
# 集群初始化时,以下节点可选为master
cluster.initial_master_nodes: ["172.16.209.23", "172.16.209.230", "172.16.209.90"]
# 一个集群中的N个节点启动后才允许进行数据恢复处理,默认是1
gateway.recover_after_nodes: 3
修改jvm内存
PATH:/etc/elasticsearch/jvm.options
默认1GB,这个值太小,很容易导致OOM。Jvm heap大小不要超过物理内存的50%,最大也不要超过32GB(compressed oop),它可用于其内部缓存的内存就越多,但可供操作系统用于文件系统缓存的内存就越少,heap过大会导致GC时间过长。
-Xms4g
-Xmx4g
ingest节点配置
只在ingest节点配置
修改es配置文件
PATH:/etc/elasticsearch/elasticsearch.yml
ingest节点上的配置文件基本一样
其他ingest节点修改node.name的值即可
cluster.name: es-cluster
node.name: es-ingest-01
node.data: false
node.master: false
path.data: /var/lib/elasticsearch
path.logs: /var/log/elasticsearch
bootstrap.memory_lock: true
network.host: 0.0.0.0
http.port: 9200
discovery.seed_hosts: ["172.16.209.23", "172.16.209.230", "172.16.209.90", "172.16.209.123", "172.16.209.150", "172.16.209.179"]
cluster.initial_master_nodes: ["172.16.209.23", "172.16.209.230", "172.16.209.90"]
gateway.recover_after_nodes: 3
修改jvm内存
PATH:/etc/elasticsearch/jvm.options
-Xms4g
-Xmx4g
data节点配置
只在data节点配置
添加数据盘
# 查看硬盘,获取额外硬盘名称
fdisk -l
fdisk /dev/vdb
n
p
回车回车回车(3个默认,使用新加的所有容量)
t
8e
w
# 创建pv
pvcreate /dev/vdb1
# 创建vg
vgcreate data /dev/vdb1 -s 16M
# 创建lv
lvcreate -n database data -l 100%free
# 格式化
mkfs.xfs /dev/data/database
# 创建挂载目录
mkdir /data
# 添加开机挂载
vim /etc/fstab
/dev/data/database /data/ xfs defaults 0 0
# 加载
mount -a
# 创建es数据目录
mkdir /data/elasticsearch
# 修改目录权限
chown elasticsearch.elasticsearch /data/ -R
修改es配置文件
PATH:/etc/elasticsearch/elasticsearch.yml
data节点上的配置文件基本一样
其他data节点修改node.name的值即可
cluster.name: es-cluster
node.name: es-data-01
node.master: false
node.ingest: false
path.data: /data/elasticsearch
path.logs: /var/log/elasticsearch
bootstrap.memory_lock: true
network.host: 0.0.0.0
http.port: 9200
discovery.seed_hosts: ["172.16.209.23", "172.16.209.230", "172.16.209.90", "172.16.209.116", "172.16.209.250", "172.16.209.89"]
cluster.initial_master_nodes: ["172.16.209.23", "172.16.209.230", "172.16.209.90"]
gateway.recover_after_nodes: 3
修改jvm内存
PATH:/etc/elasticsearch/jvm.options
默认1GB,这个值太小,很容易导致OOM。Jvm heap大小不要超过物理内存的50%,最大也不要超过32GB(compressed oop),它可用于其内部缓存的内存就越多,但可供操作系统用于文件系统缓存的内存就越少,heap过大会导致GC时间过长。
-Xms2g
-Xmx2g
至此,部署完成
启动所有es节点
systemctl enable --now elasticsearch
检查,测试
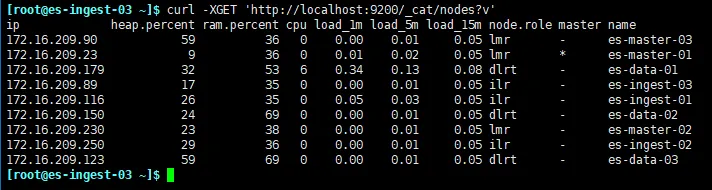
检查集群情况,在任意节点执行以下命令
curl -XGET 'http://localhost:9200/_cat/nodes?v'
结果如图
x-pack设置
步骤1、步骤2、步骤5在任意节点上操作,步骤3和步骤4在所有节点上操作
1. 创建es命令软连接
ln -sv /usr/share/elasticsearch/bin/* /usr/bin/
2. 创建节点认证中心
可以设置密码和输出文件路径和名字,这里选择默认,直接回车即可
默认输出位置:/usr/share/elasticsearch/elastic-stack-ca.p12
不同的安装方式输出的位置有所差别,但是文件名默认是一样的,找不到的时候可以find一下文件名
# 随便在任意节点上执行该命令,但是生成的文件要拷贝到其他节点上
elasticsearch-certutil ca
将生成的 elastic-stack-ca.p12 文件拷贝到每一个节点上
scp /usr/share/elasticsearch/elastic-stack-ca.p12 user@ip:/usr/share/elasticsearch/
如果不是相同的用户,拷贝过去后要注意文件权限
3. 给每个节点创建证书和密钥
可以设置密码和输出文件路径和名字,这里选择默认,直接回车即可
如果前面的创建认证中心设置了密码,这里也要输入密码,没有就回车即可
默认输出位置:/usr/share/elasticsearch/elastic-certificates.p12
# 创建证书和密钥
elasticsearch-certutil cert --ca /usr/share/elasticsearch/elastic-stack-ca.p12 --dns 本机IP --ip 本机IP
# 复制一份到es配置文件目录下
cp -a /usr/share/elasticsearch/elastic-certificates.p12 /etc/elasticsearch/
# 修改文件权限,如果不修改服务会起不来,有报错没权限
chown root.elasticsearch /etc/elasticsearch/elastic-certificates.p12
chmod 660 /etc/elasticsearch/elastic-certificates.p12
4. 修改配置文件
添加xpack的配置,启动xpack
# 开启xpack认证机制,默认是 false
xpack.security.enabled: true
# 启用ssl,默认是 false,如果不设置该参数,es会起不来,会报错提示你开启该参数
xpack.security.transport.ssl.enabled: true
# 控制证书的验证方式,默认是full
## full:其验证所提供的证书是由可信机构(CA)签名的,并且还验证服务器的主机名(或IP地址)与证书内标识的名称匹配。
## certificate:其验证所提供的证书是由可信机构(CA)签名的,但不执行任何主机名验证。
## none:其不执行对服务器的证书的验证。此模式禁用了SSL/TLS的许多安全优势,只有在经过仔细考虑后才能使用。它主要用于在尝试解决TLS错误时作为临时诊断机制;强烈反对将其用于生产集群。
xpack.security.transport.ssl.verification_mode: certificate
# 包含私钥和证书的密钥库文件的路径,它必须是Java密钥库(jks)或PKCS#12文件。不能同时使用此设置和ssl.key
xpack.security.transport.ssl.keystore.path: elastic-certificates.p12
# 包含要信任的证书的密钥库的路径。它必须是Java密钥库(jks)或PKCS#12文件。不能同时使用此设置和ssl.certificate_authorities。
xpack.security.transport.ssl.truststore.path: elastic-certificates.p12
# 启用http ssl
xpack.security.http.ssl.enabled: true
# 包含私钥和证书的密钥库文件的路径。
xpack.security.http.ssl.keystore.path: elastic-certificates.p12
# 包含要信任的证书的密钥库的路径。
xpack.security.http.ssl.truststore.path: elastic-certificates.p12
cat >> /etc/elasticsearch/elasticsearch.yml << EOF
xpack.security.enabled: true
xpack.security.transport.ssl.enabled: true
xpack.security.transport.ssl.verification_mode: certificate
xpack.security.transport.ssl.keystore.path: elastic-certificates.p12
xpack.security.transport.ssl.truststore.path: elastic-certificates.p12
xpack.security.http.ssl.enabled: true
xpack.security.http.ssl.keystore.path: elastic-certificates.p12
xpack.security.http.ssl.truststore.path: elastic-certificates.p12
EOF
修改完成后重启集群,就是重启所有节点
systemctl restart elasticsearch
5. 修改用户密码
以下命令修改的是一些内置的用户密码
elasticsearch-setup-passwords interactive
如果需要设置外置用户和密码命令如下
elasticsearch-users useradd elastic -p XXXXX -r superuser
测试
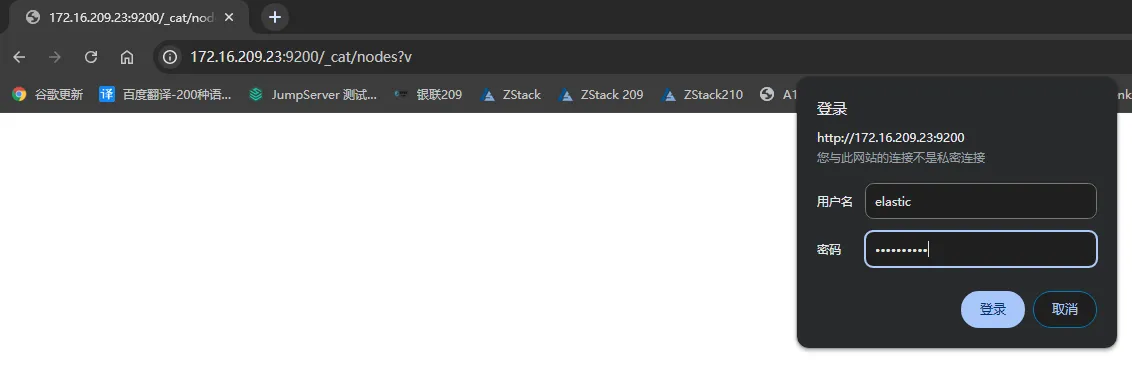
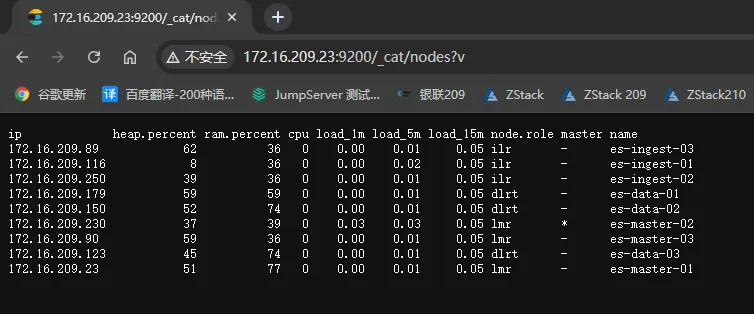
cerebro安装
建议安装在docker,本实验在安装在master-01上
- 下载rpm包并安装
# 下载
wget https://github.com/lmenezes/cerebro/releases/download/v0.9.4/cerebro-0.9.4-1.noarch.rpm
# 安装
rpm -ivh cerebro-0.9.4-1.noarch.rpm
- 修改启动文件
文件路径:/usr/lib/systemd/system/cerebro.service
# 原参数
ExecStart=/usr/share/cerebro/bin/cerebro
# 修改后参数,加了java路径
ExecStart=/usr/share/cerebro/bin/cerebro -java-home /usr/share/elasticsearch/jdk
- 添加pem证书文件
# 将p12文件转为pem,elastic-certificates.p12是之前申请的es证书文件
openssl pkcs12 -clcerts -nokeys -out /etc/cerebro/cerebro.pem -in /etc/elasticsearch/elastic-certificates.p12
- 修改配置文件
文件路径:/usr/share/cerebro/conf/application.conf
# 原参数
#data.path: "/var/lib/cerebro/cerebro.db"
data.path = "./cerebro.db"
# 修改后参数
data.path: "/var/lib/cerebro/cerebro.db"
#data.path = "./cerebro.db"
将host语句块修改为如下内容
配置如下内容后,登录无需输入密码了
hosts = [
{
host = "https://localhost:9200"
# name = "Secured Cluster"
auth = {
username = "xxxxxxx"
password = "xxxxxxx"
}
}
]
# 以下配置是添加证书认证,不然访问不了https协议的es节点
play.ws.ssl {
trustManager = {
stores = [
{ type = "PEM", path = "/etc/cerebro/cerebro.pem" }
]
}
}
play.ws.ssl.loose.acceptAnyCertificate=true
- 重启服务
# 先reload启动文件
systemctl daemon-reload
# 重启
systemctl restart cerebro
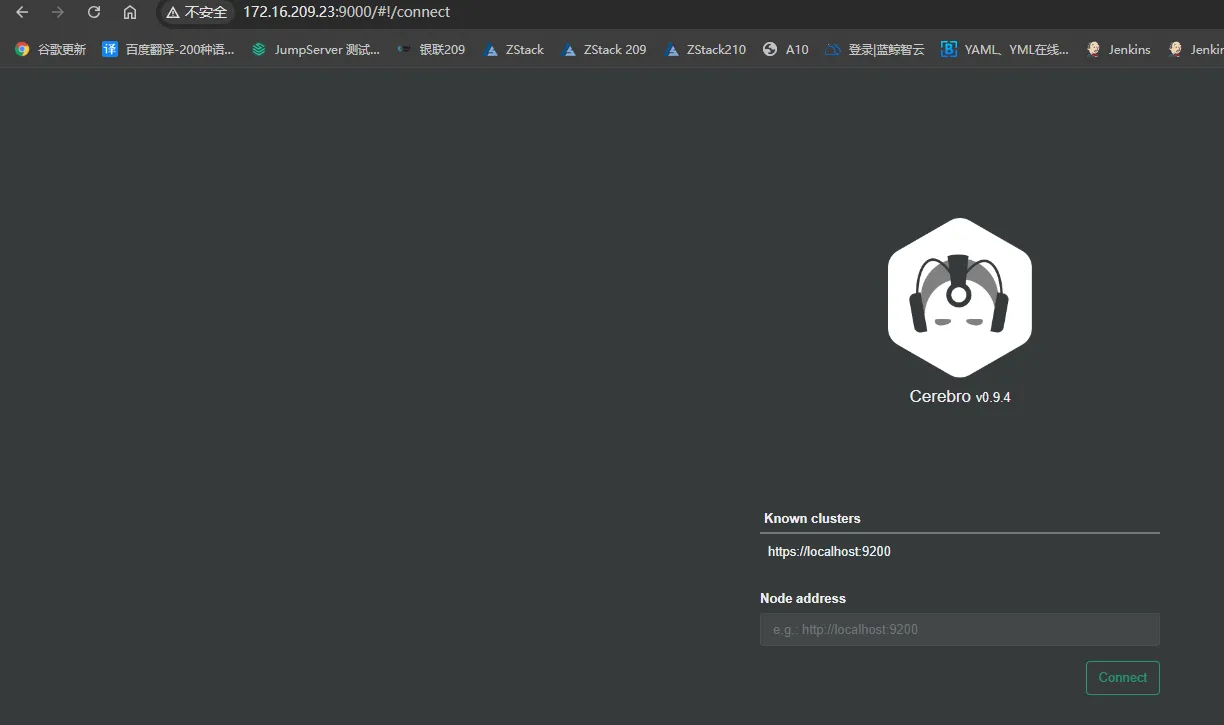
- 测试
访问地址:http://172.16.209.23:9000/
可以看事先设置好的集群,在node address下输入es地址看其他es集群,如果有做认证的话是要输入账号密码的,因为我们在配置文件配置了用户密码,访问事先设置好的集群就不用登录了
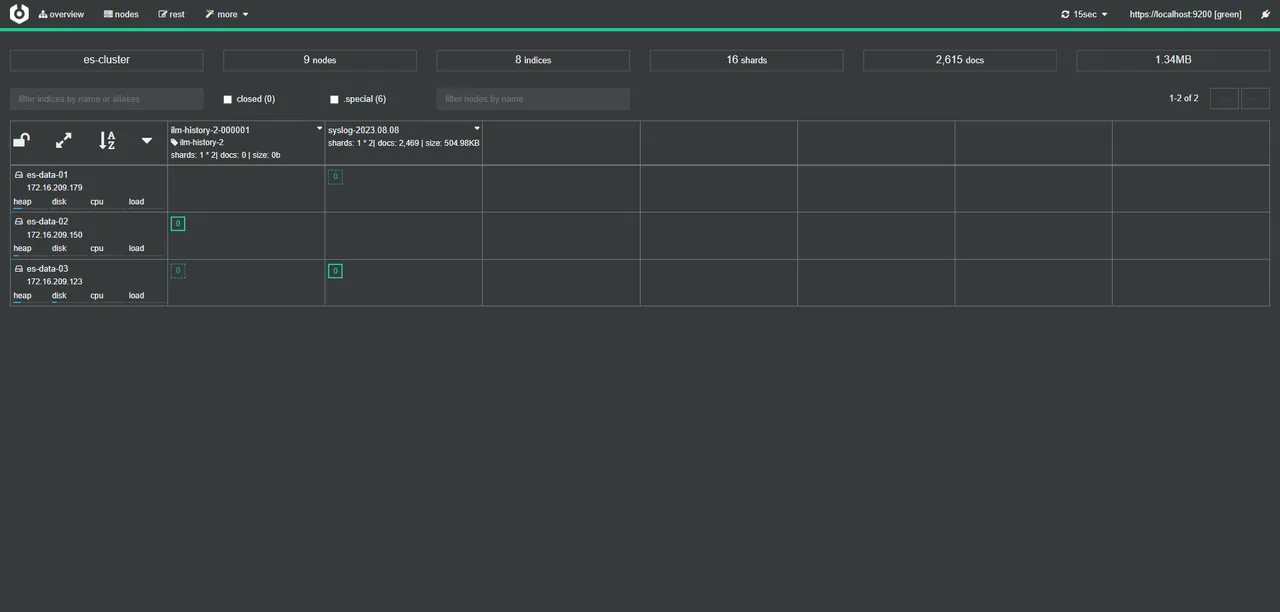
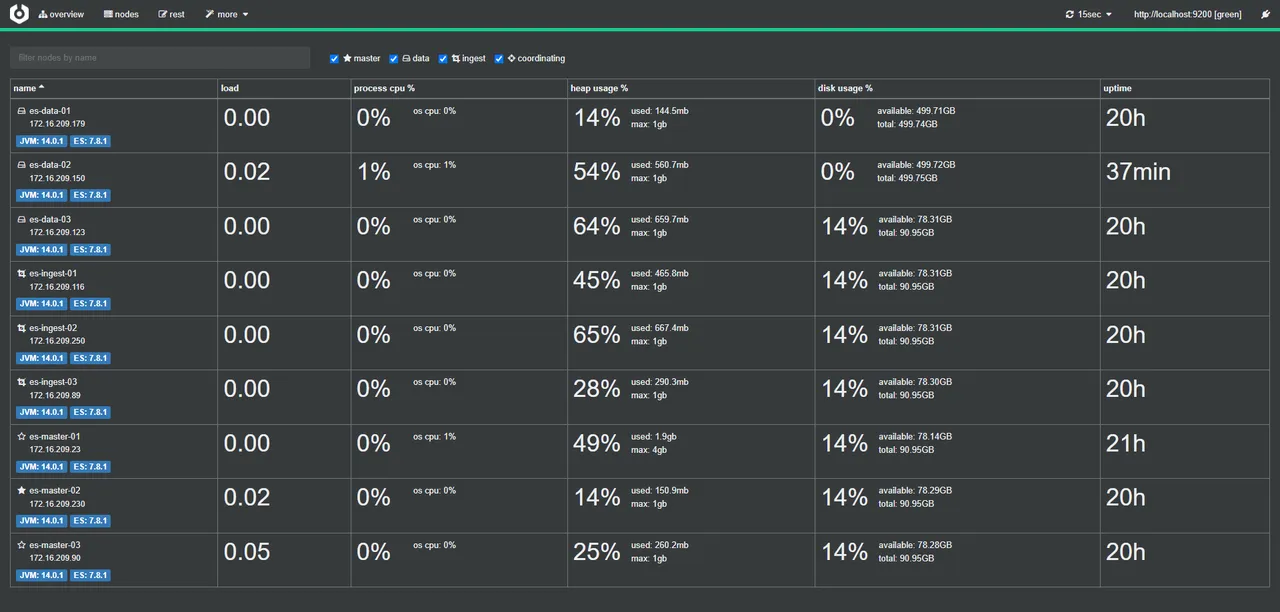
更多的Cerebro操作可以参考该文档